

После победы искусственного интеллекта (ИИ) над человеком в китайской игре го, что считалась невозможным, добившаяся этого успеха британская DeepMind занялась компьютерной игрой StarCraft II.
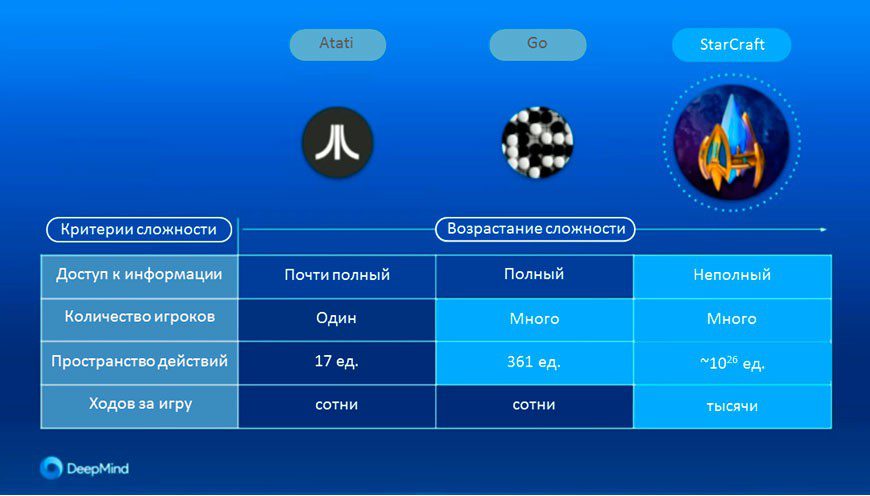
StarCraft II относится к классу «стратегия реального времени» и считается одной из самых сложных. Её история насчитывает более 20 лет, в течение которых StarCraft стала видом профессионального спорта – регулярно проводятся турниры с серьёзными денежными призами, победители этих турниров много тренируются, добиваясь мастерства.
По сравнению с настольными играми (шахматами, го) сложные компьютерные игры реального времени обладают важной особенностью: события в них развиваются подобно тому, как это происходит в реальном постоянно изменяющемся мире. В этом смысле умение ИИ успешно играть в StarCraft имеет серьёзное прикладное значение.
Прежде чем участвовать в соревнованиях по StarCraft разработчики ИИ (точнее, нейросети AlphaStar) добились предварительного успеха в более простых компьютерных играх реального времени: производства американской компании Atari (Pong, Breakout, Space Invaders, Seaquest, Beam Rider), Mario, Quake III Arena Capture the Flag и Dota 2.
В соревнованиях по Dota 2 разыгрывается 40 миллионов долларов (самый большой в киберспорте приз), так что профессиональные игроки в эту игру могут только ею и заниматься.
Совершенствоваться приходится упорными тренировками, о сложности навыков свидетельствуют данные: чемпионы в StarCraft совершают сотни действий в минуту. Роботы могут совершать десятки тысяч действий в минуту, но это, как стало ясно на практике, не главное – действия должны быть не столько быстрыми, сколько верными.
Нейросеть настраивалась специально под каждую игру, но до AlphaStar ИИ всё еще не мог соперничать с профессиональными игроками даже при упрощённых условиях (на более простых картах виртуальной «местности»).
В отличие от прежних версий ИИ AlphaStar играет на полной версии игры StarCraft II, без каких либо упрощений или ограничений.
По правилам игры участник должен выбрать одну из трёх различных инопланетных рас – зергов (нехорошие твари; насекомые с коллективным разумом, тоже своего рода «нейросеть»), протоссов («хорошие» инопланетяне) или терранов (гуманоиды). Все они имеют отличительные характеристики и способности (профессиональные игроки, как правило, играют за одну расу). Каждый игрок начинает с определённым количеством рабочих единиц, которые собирают исходные ресурсы мира игры, чтобы превратить их в сооружения, технологии и др. сущности, обеспечивающие успех. Чтобы выиграть, игрок должен тщательно сбалансировать управление своей «экономикой» и управление игровыми единицами, «юнитами». Необходимо выстроить краткосрочные и долгосрочные цели, уметь реагировать на неожиданные ситуации.
В StarCraft II, как и в детской игре «камень, ножницы, бумага», нет лучшей стратегии. Поэтому ИИ должен постоянно исследовать и расширять границы «знаний».
В отличие от шахмат или го, где игроки видят всё, в StarCraft II важная информация скрыта от игрока (находится в неразведанной части мира игры) и может быть обнаружена лишь юнитом-«разведчиком».
Как и в реальном мире, причинно-следственные связи в игре не проявляются мгновенно. Поединок может продолжаться долго, до одного часа, и действия, эффективные в начале игры, окажутся неэффективными в итоге.
В отличие от традиционной настольной игры, где игроки ходят по очереди, в StarCraft игроки должны постоянно выполнять действия в реальном времени. Сотни различных объектов нуждаются в управлении одновременно, что приводит ко множеству вариантов игры, не поддающихся, в отличие от шахмат, грубой вычислительной силе.
Для обучения AlphaStar была создана масштабируемая распределённая программа, которая поддерживает множество т.н. агентов, обучающихся во многих тысячах параллельно существующих экземпляров игры StarCraft II. Программа работает на вычислительной инфраструктуре, построенной на тензорных процессорах TPUs Google v.3.
TPUs Google v.3 - тензорные процессоры Google третьей версии. Тензорные процессоры относятся к классу нейронных процессоров и предназначены для машинного обучения. Первая версия процессора представлена в 2016 году, но Google начал эксперименты с ней не позже 2015 года.
Её производительность оценена в 420 терафлопс (операций в секунду), это примерно равно производительности суперкомпьютера IBM Blue Gene в 2006 году.
Обучение продолжалось 14 дней. За это время каждый агент провёл за игрой около 200 лет в пересчёте на реальное время игры.
Сначала нейронная сеть обучалась, изучая игры лучших киберспортсменов. AlphaStar узнала правила игры, научилась воспроизводить и комбинировать распространённые тактики. По аналогии с шахматами это был разбор партий, ранее сыгранных гроссмейстерами.
Затем была сформирована «лига AlphaStar». Для этого агентов нейросети (вначале это были копии одного и того же ИИ) заставили играть друг с другом. Получая собственный опыт, агенты стали развиваться уже по-разному. Это было соревнование, похожее на обычное – но с целью выявить победителя не среди людей, а среди по-разному обученных нейросетей.
Затем среди агентов начался искусственный отбор: выявлялись носители лучших частных навыков, затем эти навыки культивировались, передавались другим, более совершенным экземплярам нейросети. К чему это привело, видно на следующем графике: нейросеть по сложности навыков игры, которыми обладала, превзошла людей.

Только после этого робот выступил против киберспортсменов-профессионалов. Самостоятельная подготовка (обучение) перед первым турниром заняла две недели.
В киберспорте чаще всего турнир проводится как серия из пяти игр один на один (в StarCraft есть также возможность играть командами). На турнире нейросеть играла за расу протоссов. Киберспортсмены тоже играли за протоссов.
12 декабря 2018 года нейросеть сыграла с игроком высшей категории Дарио Вуншем (Dario Wünsch — 28 лет, ФРГ, специализация – зерги).
Игра 1. AlphaStar пренебрегает защитой. По ходу игры допускает незначительные ошибки, которые исправляет за счёт более точного тактического контроля ситуации. Счет 1:0.
Игра 2. AlphaStar вновь пренебрегает защитой. Упор в игре ИИ делает на получение преимущества в экономике. По ходу игры военное преимущество было у человека, однако ИИ не дал воспользоваться им за счёт лучшего контроля боевых единиц на поле боя и уклонения от решающего сражения до того, как сократил отставание в боевых единицах. Счет 2:0.
Игра 3. ИИ постоянно нападает небольшими отрядами на базу игрока и постепенно получает преимущество в игре. Все попытки киберспортсмена атаковать безуспешны, ИИ постоянно перехватывает инициативу. Счет 3:0. Турнир был выигран роботом по итогам пяти поединков, но продолжился до установления окончательного счёта.
Игра 4. Первые атаки ИИ киберспортсмен успешно отбивает. AlphaStar небольшими силами разобщает оборону игрока. Сконцентрировавшись на обороне, тот не нападает сам и проигрывает экономическую гонку. Счет 4:0.
Игра 5. По ощущениям игрока, AlphaStar плохо проводит разведку в районе своей базы и не готов к диверсиям в собственном тылу. Вунш использует эту стратегию, но внезапно обнаруживает, что ИИ действует точно так же, но успешнее и агрессивнее. Счет 5:0.
«Я был удивлен силой игры соперника», – сказал Вунш. – «AlphaStar брал хорошо известные стратегии и переворачивал их с ног на голову. Он продемонстрировал такие стратегии, с которыми я не был знаком».
После этого AlphaStar самостоятельно обучался ещё одну неделю.
19 декабря 2018 года состоялась игра с Гжегожем Коминцем (Grzegorz Komincz, 25 лет, Польша, специализация – протоссы), профессионал, один из 10 лучших игроков в мире.
Игра 1. AlphaStar пренебрегает защитой. Игрок использует это для получения преимущества. Проигрывая по общему показателю игры, AlphaStar прорывается на базу игрока и не оставляет ему шансов. Счёт 1:0.
Игра 2. AlphaStar одновременно предпринимает простые, но многочисленные действия, которые Коминц мог бы парировать, но только не одновременно – ему не хватает внимания, и инициатива упущена. Киберспортсмен пытается контратаковать, однако проигрывает из-за недостаточно эффективного управлении своими юнитами на поле боя. Счет 2:0.
Игра 3. AlphaStar впервые пытается закрыть вход на свою базу (стандартный оборонительный приём). Коминц применяет схожую тактику. Но после обмена ударами при равных возможностях побеждает ИИ. Счет 3:0.
Игра 4. Соперники включились в экономическую гонку, копят силы, не нападают. ИИ следит за тем, какие боевые единицы производит Коминц, и в ответ производит более дешёвых убийц этих боевых единиц. После серии столкновений Коминц имеет преимущество. ИИ, управляя тремя небольшими отрядами, разобщает более мощный отряд Коминца и заставляет его раз за разом ошибаться. Это новая тактика, которая ранее не была известна. Коминц теряет преимущество и проигрывает. Счет 4:0.
Игра 5. AlphaStar неоднократно пытается провести хитрую операцию по захвату рудника на базе противника, но Коминц чудом успевает парировать угрозу, потом идёт в разведку, но определить, какую стратегию выбрал ИИ, не может. Тем временем AlphaStar неожиданно создаёт военную базу при входе на его базу и не даёт игроку развиваться, постоянно увеличивая свои возможности. Счет 5:0.
По итогам серии Коминц заявил: «Я увидел игру в новом свете».

После турнира разработчики AlphaStar проанализировали игру ИИ и установили, что в играх против киберспортсменов AlphaStar в минуту совершал около 280 действий, что значительно ниже, чем среднее количество действий у профессиональных игроков (390 у Веньша и 678 у Коминца). Пиковые значения количества действий в единицу времени у ИИ также существенно отстают от показателей киберспортсменов. Но действия AlphaStar были более точными.

Разработчики проанализировали, как играл AlphaStar. ИИ постоянно контролировал всю разведанную территорию через доступный ему интерфейс с игрой, не перемещая камеру, а людям приходилось перемещаться по карте, акцентируя свое внимание в каждый момент времени только на каком-либо одном участке. Это давало AlphaStar преимущество.


Чтобы уравнять начальные условия, AlphaStar перевели на видеоинтерфейс и позволили переключать внимание около 30 раз в минуту (примерно столько раз переключают внимание Вунш и Коминц). Как и игроки-люди, эта версия AlphaStar выбирает, когда и куда перемещать камеру, восприятие игры ограничено информацией на экране.

Версия AlphaStar, использующая видеоинтерфейс, за семь дней обучения научилась играть почти так же хорошо, как и с предыдущим интерфейсом (более 7000 условных единиц сложности). Однако в пробном матче, который не шёл в зачёт турнира, Коминц победил AlphaStar, использующий видеоинтерфейс, поймав ИИ на неизвестной тому стратегии.
Гол престижа. Общий счёт – 10:1 в пользу машины.
Источник: корпоративный блог DeepMind, см., в частности, здесь и здесь.











